End-to-end learning for Self-Driving Cars
Teaching a car to drive autonomously using computer vision and deep learning.
 Image credit: Lifewire.com
Image credit: Lifewire.com
Goals
The goals / steps of this project are the following:
- Use the simulator to collect data of good driving behavior
- Build, a convolution neural network in Keras that predicts steering angles from images
- Train and validate the model with a training and validation set
- Test that the model successfully drives around track one without leaving the road.
So, what's this Data everyone talking about?
So what is this data ? For this project, Behavioral Cloning, as the name goes, driving behavior has to be taught to the car (to our model, that is!). And how do we do that ? By driving the car ourself using our keyboard of a joystick (yea , sure!). (Can you believe it? We have to do the dirty work ? The Horror!). Turns out Udacity has provided a sample dataset (God Bless those folks!) for people like us.
So what's all in there in the dataset?
Data: A Peek Inside
The data comprises of images as seen by the car at each point of time while navigating around the track, along with a CSV file, holding the entire data of the car (speed, break, throttle, images) for the entire navigation period. So the columns in the CSV are:
| Center camera image path | Left camera image path | Right camera image path | Steering angle | Speed | Throttle | Break |
First three columns are just image paths to the images as seen by the car during navigation from three cameras.
Steering angle is the values of steering wheel, lies between -1 and 1.
Speed the speed of the car for that moment.
Understanding so far
So, we have got images and steering angles...
And we have got convolutional networks...
And we know that CNN's take in images as input and can be trained to spit out some values as output. ...
We have got images and steering values...
You getting this ?
Images as input to CNNs, and steering angles as output.
But Wait, But What about the Data distribution
By now, we are all too familiar with the tricks data can play. So, lets peek inside a bit more as to how our data looks like.
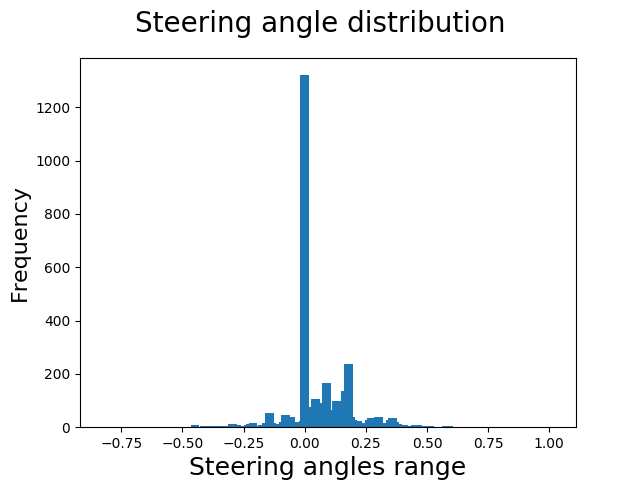
We are primarily concerned with the steering angles and images. Let's look at the distribution of the steering angles.
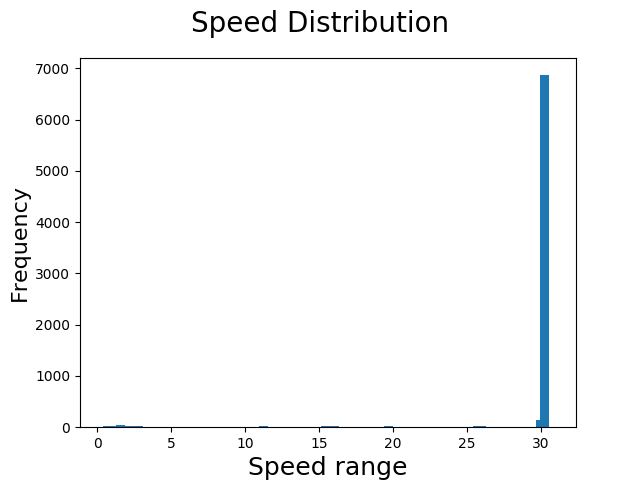
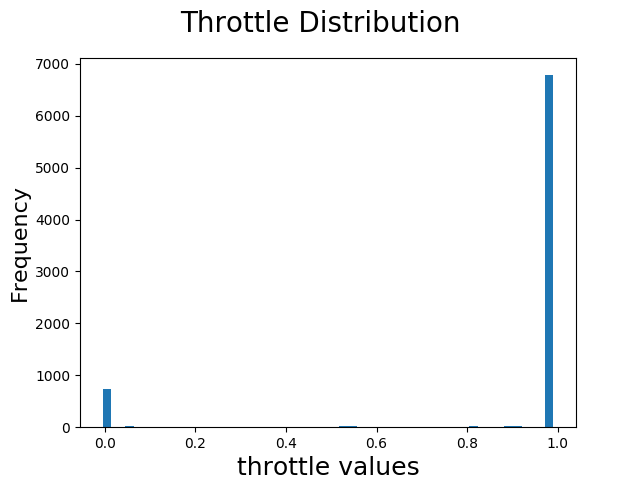
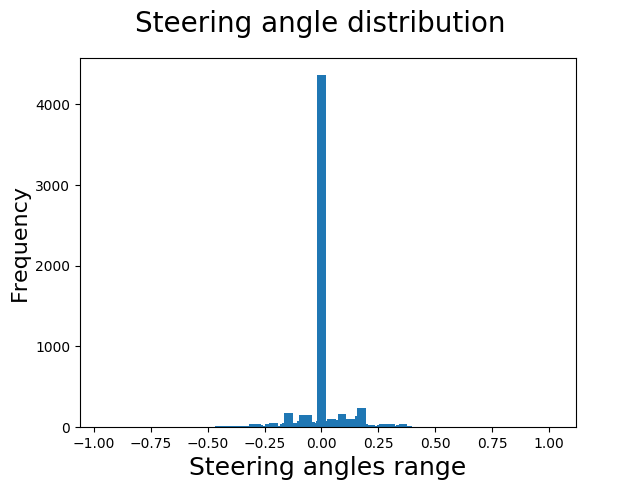
Look at that steering angle distribution, since we are primarily concerned with that. The data is highly skewed and unbalanced. Trouble!
Now ?
Let's, for now, just keep in mind what we have seen and give this problem a shot without getting into data distribution for now and see how far we can go.
The Model
The model architecture has been inspired from this post and this paper by NVIDIA.

There are two interesting bits about this architecture:
- Its a simpleified version of the architcture mentioned in the paper published by NVIDIA.
- The 1x1 convolutions at the beginning of this architecture.
To quote the author of this post,
"The first layer is 3 1X1 filters, this has the effect of transforming the color space of the images. Research has shown that different color spaces are better suited for different applications. As we do not know the best color space apriori, using 3 1X1 filters allows the model to choose its best color space"
The 1x1 convolutions are followed by 3 sets of 3x3 convolution layers, of filter sizes 16, 32 and 64. Each set is accompanied with am max pooling layer and a drop out layer. These sets are followed by 3 fully connected layers. ELU has been chosen as the activation function.
The input
Images are fed to our convolutional network, after being preprocessed with size 64x64x3.
Image Pre-processing
Image preprocessing consists of three things primarily:
1. Cropping out the car portion and the sky portion from the image.
For the task of learning the steering angle on the basis of image seen by the vehicle, there are certain elements in the image that serve no purpose. Like sky, landscape and the car portion. Lets remove these first.
Original image

Cropped Image

2. Resizing the image to a size of 64 by 64.
After having removed the unneccessry portion from the image, we need to resize the image to a size of 64 by 64 before feeding to the model.
So, that's it then ?
No! Data Augmentation remains to be done.
Data Augmentation
To geralize our model well to unknown tracks and settings, data augmentation is an important and effective tool. So what in data augmentation ?
- Flipping
Since the sample data is from first track, which has majority of left turns, the model is then inclined to have a preference for steering left (as it learns what its fed!). To make up for the scarcity of right-turn data:
- We could collect data ourselves for right turns by driving the car in the opposite direction on the track.
- Or we could just be lazy (and efficient!) and flip the images and their steering measurements.

- Image Translation



- Random Brightness



- Random Shadows



What about the Model Parameters?
Model parameters:
- Training/Test split = 0.8
- Batch Size = 32
- Number of epochs = 10
- Learning rate = 1.0e-4
- Samples per epoch = 20000
- Optimizer : Adam
And now its time to train.
Training
Having divided the dataset into train and test sets, generator is used to generate data on the fly for each epoch of training. The generator creates a batch of 32, where for each batch:
- An image is chosen from amongst the left, center and right camera images.
- The steering correction is set to be 0.25.
- The image is then augmented by using aforementioned techniques.
- The batches are then fed to the model.
Test
Using the Udacity provided simulator and drive.py file, the car can be driven autonomously around the track by executing
python drive.py model.h5
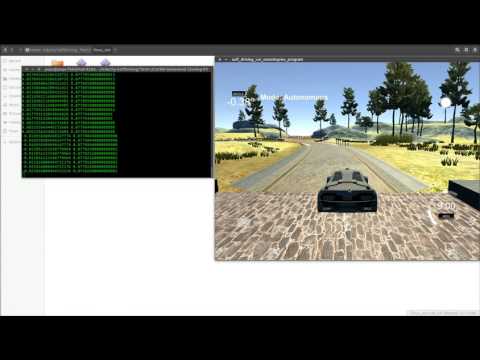
Observations
So near, yet so far. From the video, we can see that the steering angles are somewhat correct, but not completely accurate. Hence, the car turns, but not quite. And on sharp turns, the not quite factor plays a big role in taking the car out of the track. We can improve that in 2 ways:
- Retrain the model by tweaking parts of training configuations and settings such as data, model architecture etc.
- Put a leash on the car and control it using that leash.
Say, what?
Since we know that when the car turns, the steering angles do not go upto the required values, lets inflate tho steering values received from the model and give our car a help around the turns. This would require modifying the drive.py file.
if np.absolute(steering_angle)>0.07:
print('super inflating angles')
steering_angle*=2.5
throttle = 0.001
elif np.absolute(steering_angle)>0.04:
print('inflating angles')
steering_angle*=1.5
throttle = 0.1
Test again
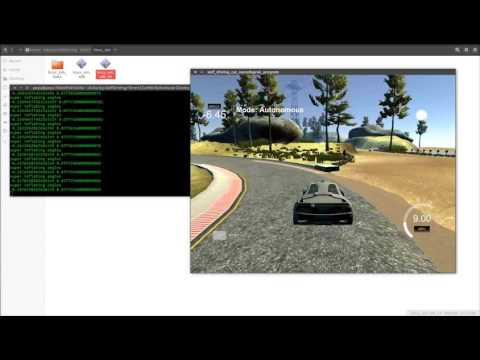
It works!! Woohoo!!
Test on Track 2
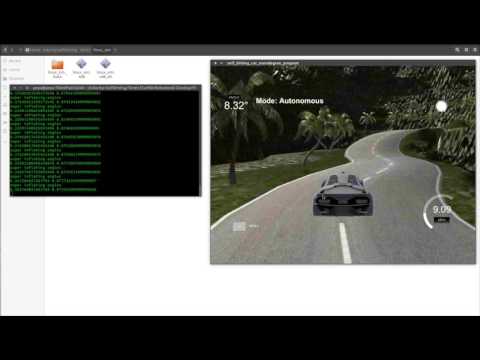
Well, so long! That ended up early. Time to move to our first strategy.
Resolve the Data distribution
A quick look into the data reveals that there are 6148 number of rows in our data that have steering values less than 0.01. Which justifies our model's tendency to move straight and not being able to make sharp turns. If we removed around 70% of those, we would be left with 3732 data points in total, which would be comparatively balanced.
Now Test
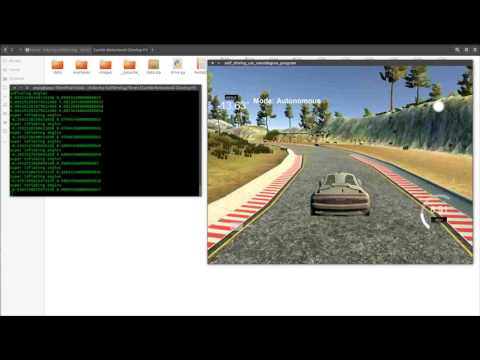
It works. But as we can see, after removing the data points for straight path navigation, there's a swivel in the movement of the car, which means, the learning could be improved a bit here. Also, at the sharp turns, it no longer turns at the last moment, relying on the control code to get it through, signifying improved learning for turns.
Lets test this on track 2.
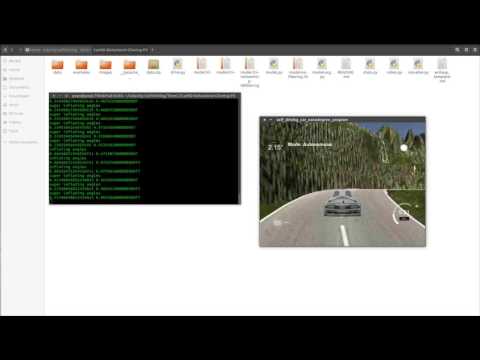
Hurray! It works here as well.
Also, the model works fine on track 1 even if the leash code is removed. Is the model self sufficient now ? Not quite. It doesnt work on track 2.
There's still a bit of "going-straight" tendency in the model, which isnt letting the car make very sharp turns.
Thoughts
Having seen in the Traffic Sign Classification project and confirmed with this one, data is everything. This solution works, but it could be improved in a number of ways:
1. Different model architecture
Altought the dataset is not that large or complex, still it could be insightful how some of the other arhitectures
2. Data collection
We could also try being less lazy and actually try collecting data ourselves, the way it is suggested with recovery and regular laps. The point is, we could see what effect does more data have on this implementation and how that would change things.
3. Driving like a human
Right now, the car is able to drive around both tracks, but let's face it, if it were a real world driving, it would end up getting ticktets even before reaching the first turn. We could try teaching the model lane driving, which would mean some added data augmentation techiniques and better data to work with.
4. Break and Throttle
Currently, our convolutional neural network only predicts the values of steering angles using images. It could be enhanced to predict the throttle and break values as well.
P.S - Here's the link to the Github Repo.
Piyush Papreja
Software Developer
My research interests include music information retrieval, recommendation systems and web.