Building Music Playlists Recommendation System
Content taken from our paper titled “Representation, Exploration, and Recommendation Of Music Playlists”
 Photo by Mariah Ashby on Unsplash
Photo by Mariah Ashby on Unsplash
Quick Summary
Goal
The goal of this work is to represent playlists in a way which captures the true essence of the playlist, i.e. information such as type, genre, variety, order, and the number of songs in the playlist, and which can be used for tasks such as playlist discovery and recommendation.
Contribution
- Built a recommendation engine for playlists using sequence-2-sequence learning.
- Evaluated the work using a recommendation-based evaluation task.
- Assembled a dataset of 1 million Spotify playlists and 13 million tracks for this work.
Applications
Playlist Discovery/Recommendation Engine
Our system can be used for playlist discovery and recommendation. Given a query playlist, the system returns the playlists from the database which are most similar to the input playlist.
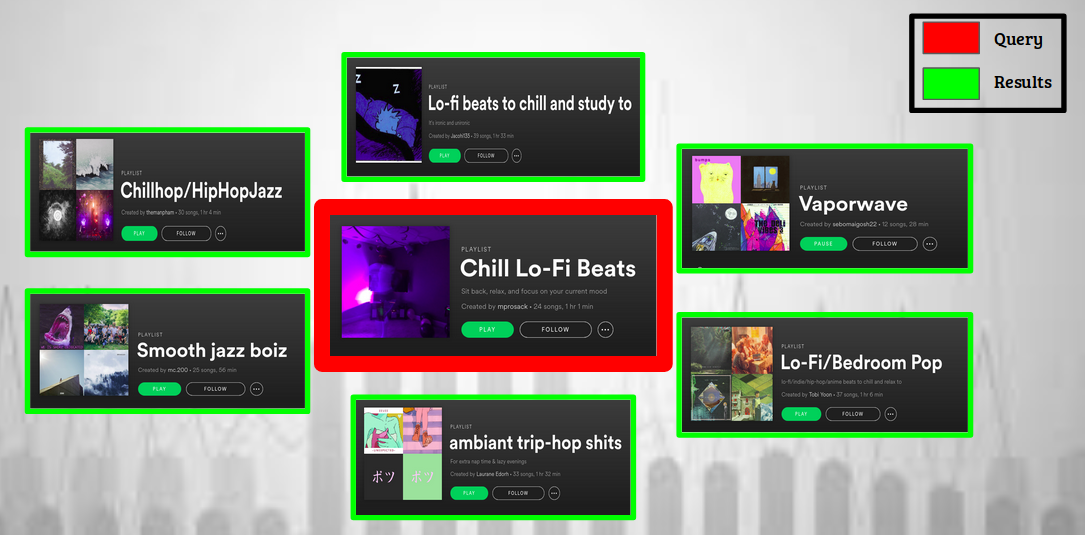
Image displaying the usage for our playlist recommendation engine. The system returns playlists most similar to the query playlist
Developer Friendly Outline
Here’s a quick outline of our proposed approach:
- Download playlists data using Spotify developer API and everynoise.com.
- Filter the data by removing noise (rare songs, duplicate songs, outlier sized playlists, etc.)
- Train a sequence-2-sequence⁹ model over the data to learn playlist embeddings.
- Annotate the data (songs and playlists) for genre information.
- Evaluate the embeddings using our proposed evaluation tasks.
- Build a recommendation engine by populating a KD-tree with the learned playlist embeddings, and retrieving search results by utilizing the nearest neighbor approach.
Introduction
Playlists have become a significant part of our music listening experience today. There are over three billion of these on Spotify alone¹. There are playlists for every moment, every mood, every season, and so on. With millions of songs at their fingertips, users today have grown accustomed² to:
- Immediate attainment of their music demands.
- An extended experience. While recommendation engines service the first aspect, playlists handle the second aspect of this changing behavior, making playlist recommendation extremely important, both for the users and music companies.
What is a Playlist, and Why Should I Care?
“A playlist is a set of songs supposed to be listened together, usually in an explicit order.” ³
Playlists are extremely important today from the perspective of both users and music researchers. From the user perspective, playlists are an effective way to discover new music and artists. From the researcher perspective, it is important to understand that music is consumed through listening and playlists formalize that listening experience³. Playlists are a unit component which can be discovered and recommended, just like artists, songs and albums.
”From the researcher perspective, it is important to understand that music is consumed through listening and playlists formalize that listening experience” ³
So What’s the problem?
As mentioned before, owing to the meteoric rise in the usage of playlists, playlist recommendation is crucial to music services today. However, over the past couple of years, from a research perspective, playlist recommendation has become analogous to playlist prediction/creation⁷ ⁸ and continuation⁵ ⁶ rather than playlist discovery. However, playlist discovery forms a significant part of the overall playlist recommendation pipeline, as it is an effective way to help users discover existing playlists on the platform.
Discovery is the name of the Game
Our work aims to represent playlists in a way which can be used to discover and recommend existing playlists. We use sequence-to-sequence learning⁹ to learn embeddings for playlists that capture their semantic meaning without any supervision. These fixed-length embeddings can then be used for recommendation purposes.
Intuition Behind the Approach
Why Sequence-to-sequence Learning?
The primary intuition behind choosing sequence-to-sequence learning is that playlists can be interpreted just as sentences, and songs as words in a sentence. In the past few years, sequence-to-sequence learning has been widely used to learn effective sentence embeddings in applications like neural machine translation¹⁰. We make use of the relationship playlist:songs:: sentences:words, and take inspiration from research in the field of natural language processing to model playlist embeddings the way sentences are embedded.
We make use of the relationship playlist:songs :: sentences: words, and take inspiration from research in natural language processing to model playlist embeddings the way sentences are embedded.
Sequence-to-Sequence Learning
The name sequence-to-sequence learning in its very core implies that the network is trained to take in sequences and output sequences. So instead of predicting single word, the network outputs the entire sentence, which could be a translated in a foreign language, or the next predicted sentence from the corpus, or even the same sentence if the network is trained like an autoencoder.
For this work, we use seq2seq framework as an autoencoder where the task of the network is to reconstruct the input playlist and in doing so, learn a compact representation of the input playlist, which captures the properties of the playlist.

The overall concept of using seq2seq network like an autoencoder.
Seq2seq Models
We use the Attention technique for the seq2seq models used in this work to learn the playlist embeddings which capture the long-term dependencies between the songs in the playlist because of the relatively longer length of playlists (50–1000 songs). We experiment with 2 variants of seq2seq models:
- Unidirectional seq2seq networks
- Bidirectional seq2seq networks
A bidirectional seq2seq network is different from the unidirectional variant in the sense that a bidirectional RNN is used, meaning the hidden state is the concatenation of a forward RNN and a backward RNN that read the sequences in two opposite directions. This allows the network to capture more contextual information for the decoder to predict the output symbol.
Data: Curation, Filtering, and Annotation
Need
For this work, we need a list of playlists (sentences) with each playlist consisting of a list of songs (words). For solving this problem in it’s simplest form, we need just the playlist IDs and the song IDs mapped with the appropriate playlist IDs.
Dataset Creation
We download the data using the Spotify Web API. To collect a big enough set of terms to query the Spotify system, we use everynoise.com. This interactive website contains a list of some 2600+ genres, graphed out according to their relationship with each other, along with an audio example for each genre. We parse the data from the home page of this website and get the list of all the genres. Then for each genre, we download playlists (along with the corresponding song information) using the Spotify Web API. The whole flow is shown in Fig 1.

Fig 1: Data download workflow
Here are the downloaded data details:
- 1 Million Playlists
- 3 Million Artists.
- 13 Million Tracks
- 3 Million Unique Tracks
- 3 Million Albums
- 2680 Genres
Data Filtering
We follow [1] in doing the data clean up by removing the rare tracks, and outlier sized playlists (having a number of songs less than 10 or greater than 5000). This leaves up with 755k unique playlists and 2.4 million unique tracks.
Annotation

Image of a subset of genres taken from everynoise.com
Problem: Genres, Genres Everywhere
Although this step is not directly needed for the training part, however, it is crucial for the evaluation phase. This step aims to label the playlists with their appropriate genre. There are certain problems with the information available so far:
- Spotify provides genre information for the artist, but not the song. Labeling the song genre same as the artist genre would not be entirely correct as an artist can have songs of different genres.
- Assigning the songs the same genre as that of the playlist, which in turn is derived from the query term for which it was fetched, would be problematic. The issue in going this route is the subjectivity associated with it. Provided this fine-grained annotation, what would be the difference between soft rock, 80’s rock, classic rock, and rock from the perspective of classification?
Hence, we need to bring down the number of genres (output labels) from 2680 to a more manageable number.
Proposed Solution
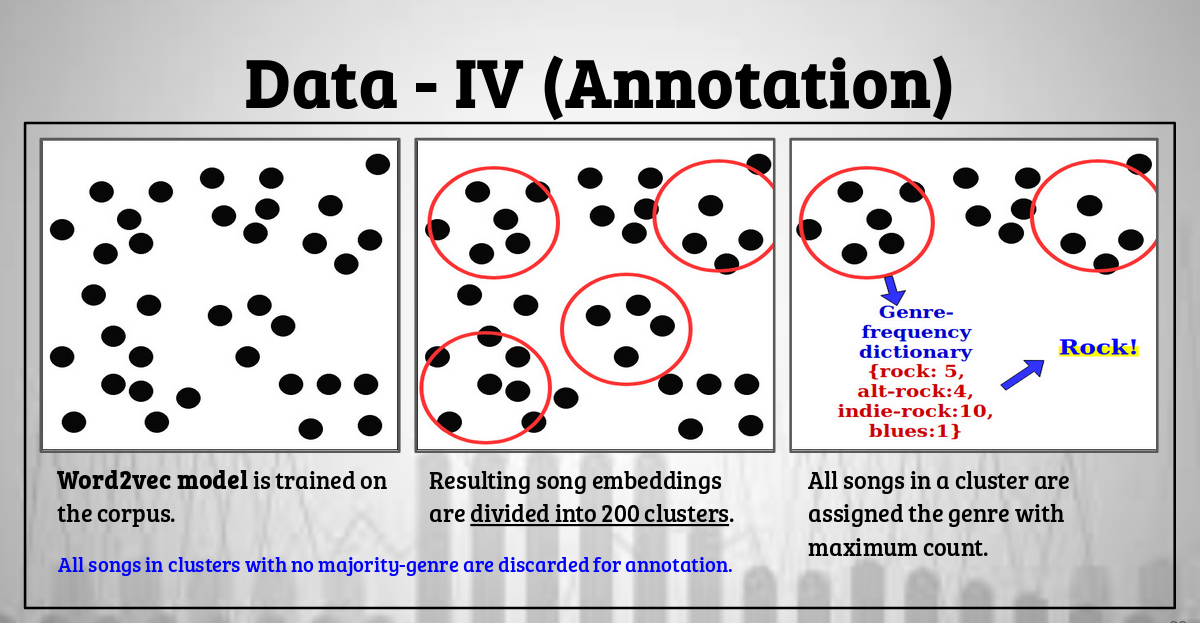
Data annotation workflow
- To solve for this, we train a word2vec¹¹ model on our corpus to get song embeddings, which capture the semantic characteristics (such as genre) of the songs by their co-occurrence in the corpus.
- The resulting song embeddings are then clustered into 200 clusters (arbitrarily chosen number in an attempt to maintain the balance between the feasibility of the annotation process and size of formed clusters. Smaller cluster size and lesser annotation time are desired).
For each cluster:
• Artist genre is applied to each corresponding song and a genre-frequency (count) dictionary is created. A sample genre-count dictionary for cluster with 17 songs would look like {rock: 5, indie-rock:3, blues: 2,soft-rock: 7}
• From this dictionary, the genre having a clear majority is assigned as the genre for all the songs in that cluster.
• All the songs in a cluster with no clear genre majority are discarded for annotation.
Based on the observed genre-distribution in the data, and as a result of clustering sub-genres (such as soft-rock) into parent genres (such as rock), the genres finally are chosen for annotating the clusters are:
Rock, Metal, Blues, Country, Reggae, Latin, Electronic, Hip Hop Classical.
To validate our approach, we train a classifier on our dataset consisting of annotated song embeddings. With training and test set kept separate at the time of training, we achieve a 94% test accuracy.

t-SNE plot for genre-annotated songs, with 1000 sampled songs for each genre
For playlist-genre annotation, only the playlists having all the songs annotated, are considered for annotation. Further, only those playlists are assigned genres for which more than 70% of the songs agree on a genre.
Evaluation
Since the aim of our work is to learn playlist embeddings which can be used for recommendation, we evaluate the quality of embeddings using a recommendation task.
Recommendation Task
The recommendation being inherently subjective in nature is best evaluated by having user-labeled data. However, in the absence of such annotated datasets, we evaluate our proposed approach by measuring the extent to which the playlist space created by the embedding models is relevant, in terms of the similarity of genre and length information of closely-lying playlists. We use the Approximate Nearest Neighbors Algorithm using Spotify ANNOY library¹³ to populate the tree structure with the playlist embeddings. A query playlist is randomly selected and the search results are compared with the queried playlist in terms of genre and length information. There are nine possible genre labels. For comparing length, ten output classes (spanning the range {30…250} corresponding to bins of size 20 are created. An average of 100 precision values for each query is considered.
Baseline Comparison
To evaluate the performance of our proposed technique, we need some sort of baseline performance as well. As our baseline model, we experiment with a weighted variant of Bag-of-words model¹⁴, which uses a weighted averaging scheme to get the sentence embedding vectors followed by their modification using singular-value decomposition (SVD). This method of generating sentence embeddings proves to be a stronger baseline compared to traditional averaging.
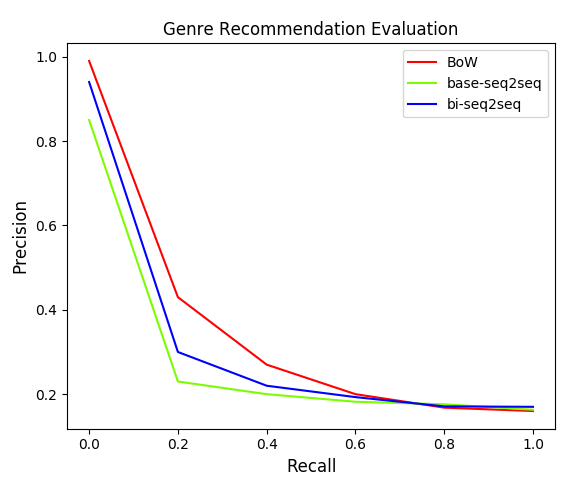
Results
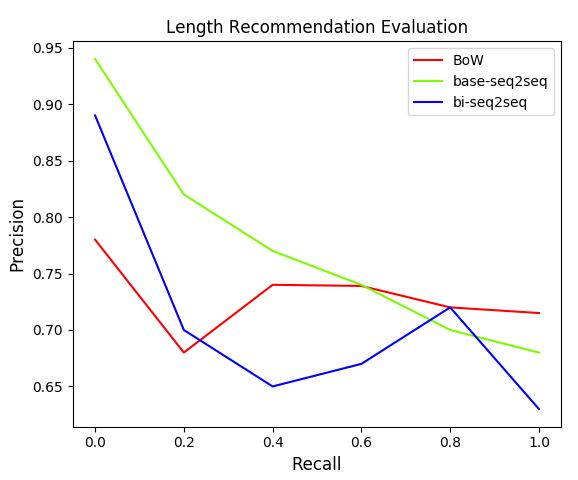
The Recommendation task, as shown in Figure below, captures some interesting insights about the effectiveness of different models for capturing different characteristics. Firstly, high precision values demonstrate the relevance of the playlist embedding space which is the first and foremost expectation from a recommendation system. Also, BoW models capture genre information better than seq2seq models, while length information is better captured by the seq2seq models, demonstrating the suitability of different models for different tasks.
Applications
One of the direct applications of this work is a recommendation engine for playlists. Given a query, the system would recommend/retrieve similar playlists form the corpus. The tree data structure discussed in Recommendation Task section can be directly used for this purpose. Given a query playlist, its k-nearest neighbors would be the most similar items to it and would be the system recommendations. Demonstration for our work can be seen in the video.
Recommendation System Demo video
And that’s that. We have presented a seq2seq based approach for learning playlist embeddings, which can be used for tasks such as playlist discovery and recommendation. Our approach can also be extended for learning even better playlist-representations by integrating content-based (lyrics, audio, etc.) song-embedding models, and for generating new playlists by using variational sequence models. In the paper, there are many more evaluation techniques for assessing the quality of playlist embeddings with respect to the encoded information, which is out of scope for this post. I will be discussing that in another post. Until next time!
P.S — Here’s the link to the paper.
References
[1] https://newsroom.spotify.com/2018-10-10/celebrating-a-decade-of-discovery-on-spotify/
[2] Keunwoo Choi, George Fazekas, and Mark Sandler. Towards playlist generation algorithms using rnns trained on within track transitions.arXiv preprint arXiv:1606.02096, 2016
[3] Fields, Ben, and Paul Lamere. “Finding A Path Through The Jukebox — The Playlist Tutorial, ISMIR.” ISMIR, Utrecht (2010).
[4] De Mooij, A. M., and W. F. J. Verhaegh. “Learning preferences for music playlists.” Artificial Intelligence 97.1–2 (1997): 245–271.
[5] Ching-Wei Chen, Paul Lamere, Markus Schedl, and Hamed Zamani. Recsys challenge 2018: Automatic music playlist continuation. InProceedings of the 12th ACM Conference on Recommender Systems, pages 527–528.ACM, 2018
[6] Maksims Volkovs, Himanshu Rai, Zhaoyue Cheng, Ga Wu, Yichao Lu, and Scott Sanner. Two-stage model for automatic playlist continuation at scale. In Proceedings of the ACM Recommender Systems Challenge 2018, page 9. ACM, 2018
[7] Andreja Andric and Goffredo Haus. Automatic playlist generation based on tracking user’s listening habits.Multimedia Tools and Applications, 29(2):127–151, 2006.
[8] Beth Logan. Content-based playlist generation: Exploratory experiments. InISMIR, 2002.
[9] lya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. Advances in neural information processing systems, pages 3104–3112, 2014.
[10] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473, 2014.
[11] Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
[12] Anita Shen Lillie.MusicBox: Navigating the space of your music. PhD thesis, Massachusetts Institute of Technology, 2008
[13] Bernhardsson, E. “ANNOY: Approximate nearest neighbors in C++/Python optimized for memory usage and loading/saving to disk.” GitHub https://github. com/spotify/annoy (2017).
[14] Arora, Sanjeev, Yingyu Liang, and Tengyu Ma. “A simple but tough-to-beat baseline for sentence embeddings.” (2016).
Piyush Papreja
Software Developer
My research interests include music information retrieval, recommendation systems and web.